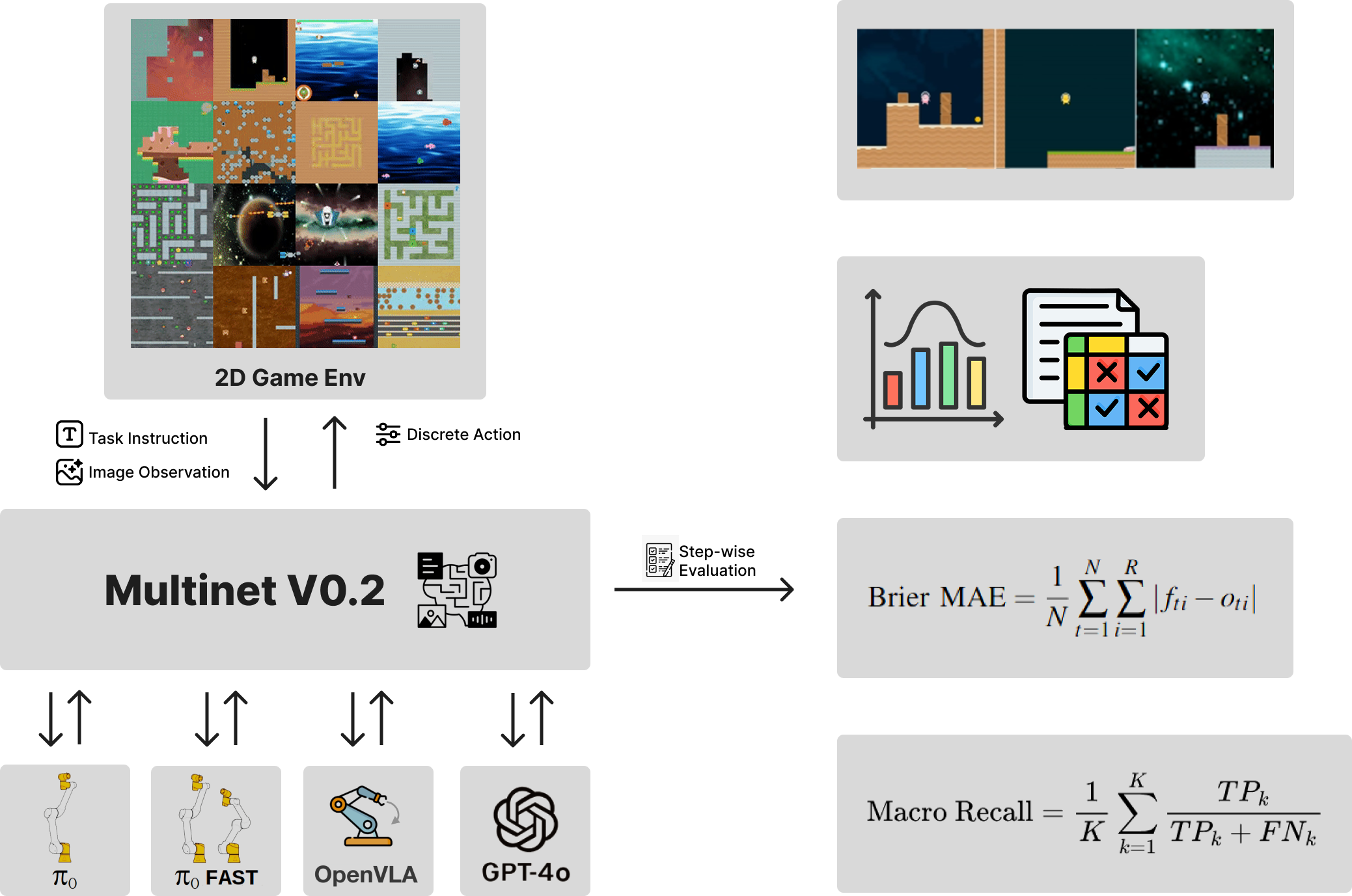
 MultiNet
MultiNet
















Results and Analysis
We find significant limitations in model performance arising from architectural constraints, training paradigms, and input-output biases inherent to the models. The stark domain discrepancy between training data—primarily continuous-action robotics datasets, and general web-scale vision language data—and discrete-action game environments emerged as a critical barrier to effective zero-shot generalization. We also identified notable differences in model behaviors linked directly to their architectures, training strategies, and input/output processing techniques.
Overall Performance
Frequency of predicted action classes
Models
Procgen Datasets
Correlation matrix between image entropies and model performance
OpenVLA's robust action-space clamping technique consistently provided superior generalization, minimizing invalid outputs and exhibiting relative resilience to out-of-distribution scenarios. Conversely, autoregressive models like GPT-4x displayed substantial difficulties in generalizing, especially under complex image conditions, and frequently defaulted to overly simplistic or biased action choices. Additionally, Pi0 models showed intermediate performance influenced heavily by their diffusion-based (Pi0 Base) or autoregressive (Pi0 FAST) decoding methods, with Pi0 FAST notably sensitive to image complexity and unable to restrict majority of its predictions to a desired output range. For a more thorough look at the results and our analysis, please refer to the paper.