Vision-language-action (VLA) models represent a promising direction for developing general-purpose robotic systems, demonstrating the ability to combine visual understanding, language comprehension, and action generation. However, systematic evaluation of these models across diverse robotic tasks remains limited. In this work, we present a comprehensive evaluation framework and benchmark suite for assessing VLA models. We profile three state-of-the-art VLM and VLAs —GPT-4o, OpenVLA, and JAT—across 20 diverse datasets from the Open-X-Embodiment collection, evaluating their performance on various manipulation tasks. Our analysis reveals several key insights:
All 3 models - HuggingFace's JAT (novel generalist model, OS implementation of GATO), GPT-4o (SoTA VLM), and OpenVLA (SoTA VLA) were evaluated across the 20 diverse datasets from the Open-X-Embodiment collection listed below, thus evaluating their performance on various manipulation tasks. JAT was also evaluated on 33 more OpenX Embodiment datasets, and GPT-4o was evaluated on 2 more OpenX Embodiment datasets. You can find the results of these evaluations in the paper
| Dataset Name | Registered Dataset Name | In Pretraining for OpenVLA | Action Space Type |
|---|---|---|---|
| Jaco Play | jaco_play | ✓ | 4D (1 grip, 3 pos) |
| Berkeley Cable Routing | berkeley_cable_routing | ✓ | 7D (3 ang, 3 pos, 1 term) |
| NYU Door Opening | nyu_door_opening_surprising_effectiveness | 8D (1 grip, 3 ang, 3 pos, 1 term) | |
| VIOLA | viola | ✓ | 8D (1 grip, 3 ang, 3 pos, 1 term) |
| Berkeley Autolab UR5 | berkeley_autolab_ur5 | ✓ | 8D (1 grip, 3 ang, 3 pos, 1 term) |
| TOTO | toto | ✓ | 7D (3 ang, 3 pos, 1 term) |
| Columbia PushT | columbia_cairlab_pusht_real | 8D (1 grip, 3 ang, 3 pos, 1 term) | |
| NYU ROT | nyu_rot_dataset_converted_externally_to_rlds | 7D (3 pos, 3 ang, 1 grip) | |
| Stanford HYDRA | stanford_hydra_dataset_converted_externally_to_rlds | ✓ | 7D (3 pos, 3 ang, 1 grip) |
| UCSD Kitchen | ucsd_kitchen_dataset_converted_externally_to_rlds | ✓ | 8D (3 pos, 3 ang, 1 grip, 1 term) |
| UCSD Pick Place | ucsd_pick_and_place_dataset_converted_externally_to_rlds | 4D (3 vel, 1 grip torque) | |
| USC Cloth Sim | usc_cloth_sim_converted_externally_to_rlds | 4D (3 pos, 1 grip) | |
| Tokyo PR2 Fridge | utokyo_pr2_opening_fridge_converted_externally_to_rlds | 8D (3 pos, 3 ang, 1 grip, 1 term) | |
| Tokyo PR2 Tabletop | utokyo_pr2_tabletop_manipulation_converted_externally_to_rlds | 8D (3 pos, 3 ang, 1 grip, 1 term) | |
| UTokyo xArm Pick-Place | utokyo_xarm_pick_and_place_converted_externally_to_rlds | 7D (3 pos, 3 ang, 1 grip) | |
| Stanford MaskVIT | stanford_mask_vit_converted_externally_to_rlds | 5D (3 pos, 1 ang, 1 grip) | |
| ETH Agent Affordances | eth_agent_affordances | 6D (3 vel, 3 ang vel) | |
| Imperial Sawyer | imperialcollege_sawyer_wrist_cam | 8D (3 pos, 3 ang, 1 grip, 1 term) | |
| ConqHose | conq_hose_manipulation | 7D (3 pos, 3 ang, 1 grip) | |
| Plex RoboSuite | plex_robosuite | 7D (3 pos, 3 ang, 1 grip) |
We benchmark a SoTA VLM (GPT-4o), a SoTA VLA (OpenVLA), and a novel generalist model (JAT) in zero-shot settings across 20 diverse datasets from the Open-X-Embodiment collection. In order to evaluate each of these models on offline Robotics trajectories, we utilize Mean Squared Error (MSE) as a metric to compare the predicted action of the model and the ground truth action from the dataset on a per-timestep basis. This metric seemed most appropriate given the offline nature of the dataset, and no access to physical robots or the simulated environments corresponding to the datasets. The MSEs per timestep are averaged over all the timesteps in the eval split of the dataset to give an Averaged Mean Squared Error (AMSE) for the whole dataset. This metric is used to compare the performance of the different models given a dataset.
In order to account for the difference in the scales of the action spaces (and therefore, the MSEs) across datasets, we normalize the per-timestep MSEs using the minimum and maximum MSE values observed in the evaluation (timestep MSE - min MSE) / (max MSE - min MSE). These are then averaged over the entire dataset to give a Normalized Average Mean Squared Error (NAMSE) for each dataset. The NAMSE is a metric that allows comparison of a given model's performance across different datasets.
We also assess successful completion of an episode in a given task, by comparing final predicted actions with ground truth final actions. While this serves as an approximate measure of task completion, it provides valuable insights into the models' ability to reach target states across trajectories. We will be actively updating this benchmark as we profile SoTA VLMs and VLAs on more OpenX-Embodiment datasets, other RL and Robotics datasets, and in few-shot and fine-tuned settings.


We conduct thorough quantitative analyses to observe the performance of the different models across different OpenX Embodiment datasets. We investigate the performance difference between models by comparing their AMSE scores across datasets. We also do a model-specific analysis to understand performance patterns of models that may be attributable to several architectural and training differences between them, which in turn helps guide future research in this direction. While absolute performance metrics like AMSE provide insight into task-specific capabilities, looking into the NAMSE scores allows us to understand how each model performs across different tasks relative to its own capabilities. NAMSE proves to be particularly valuable for understanding inherent task difficulty and model behavior patterns independent of action space scale. Here is an overview of our analysis:
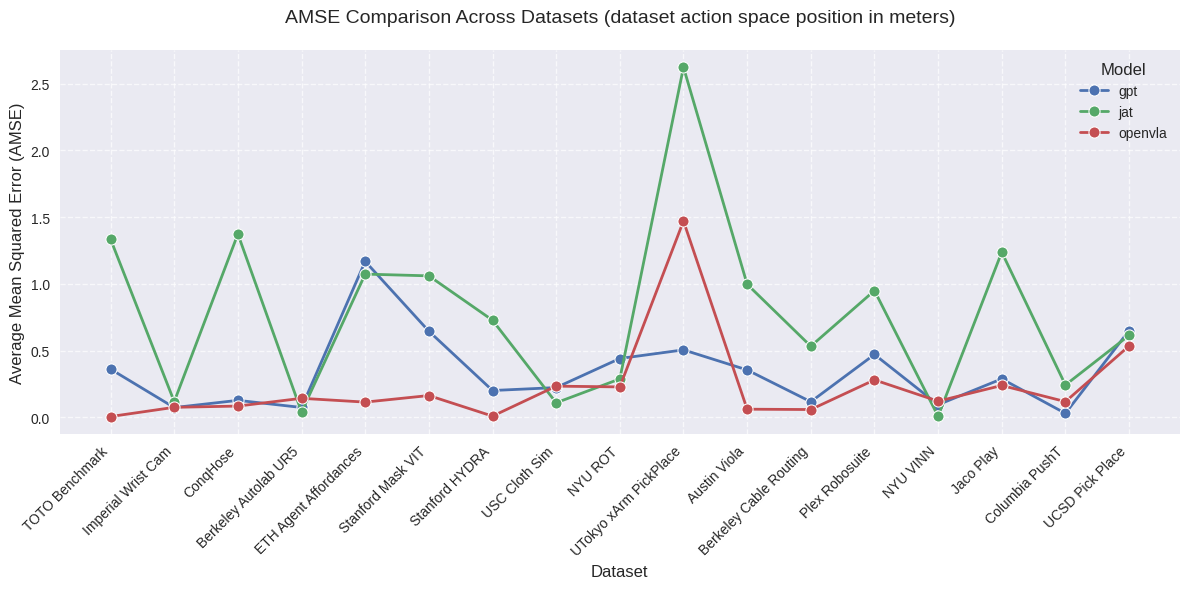
AMSE across all datasets
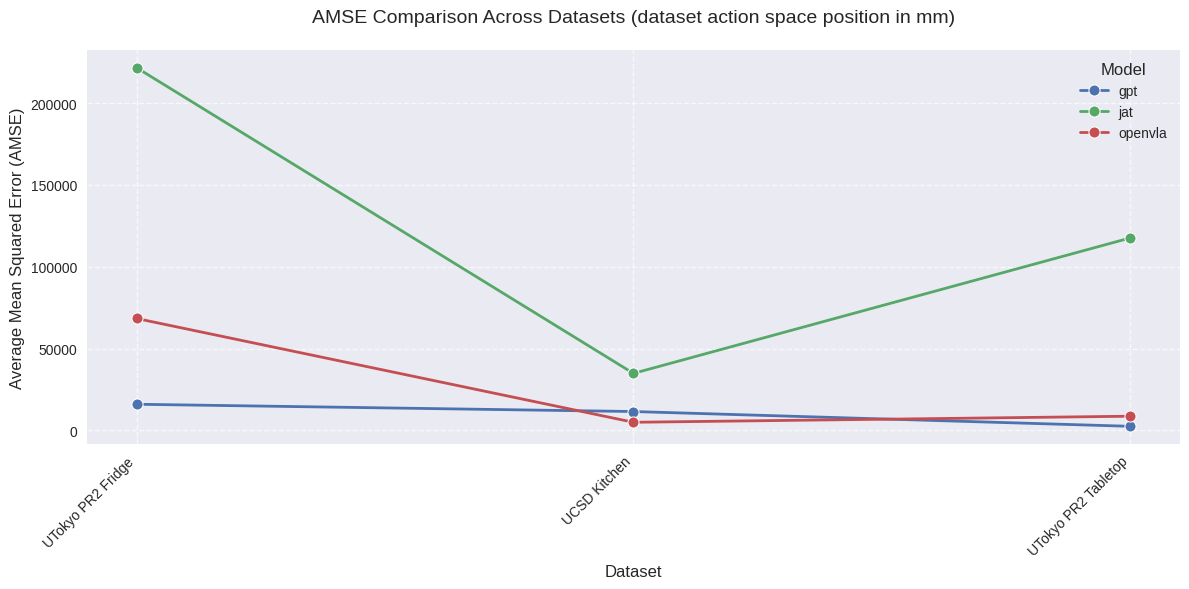
AMSE across datasets with the action space unit in millimeters
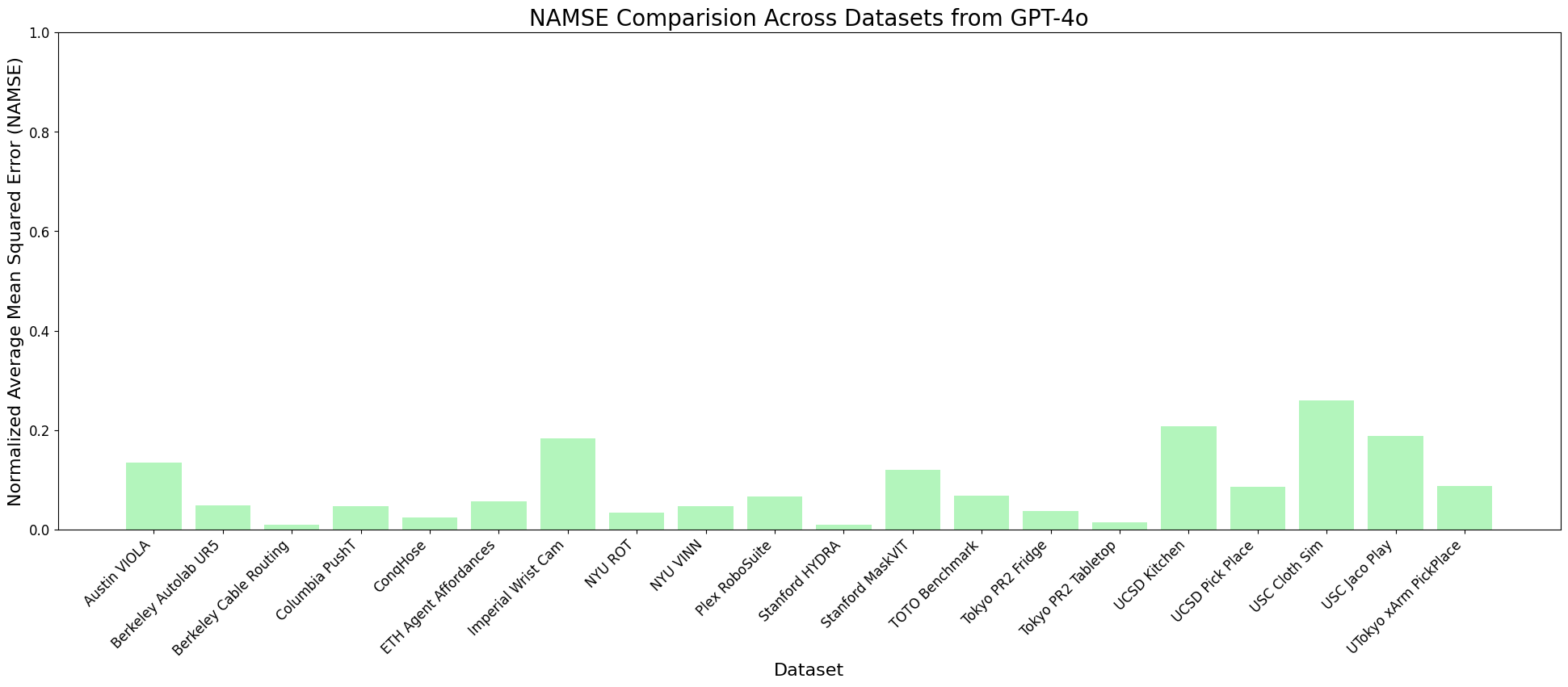
Normalized AMSE For GPT-4o
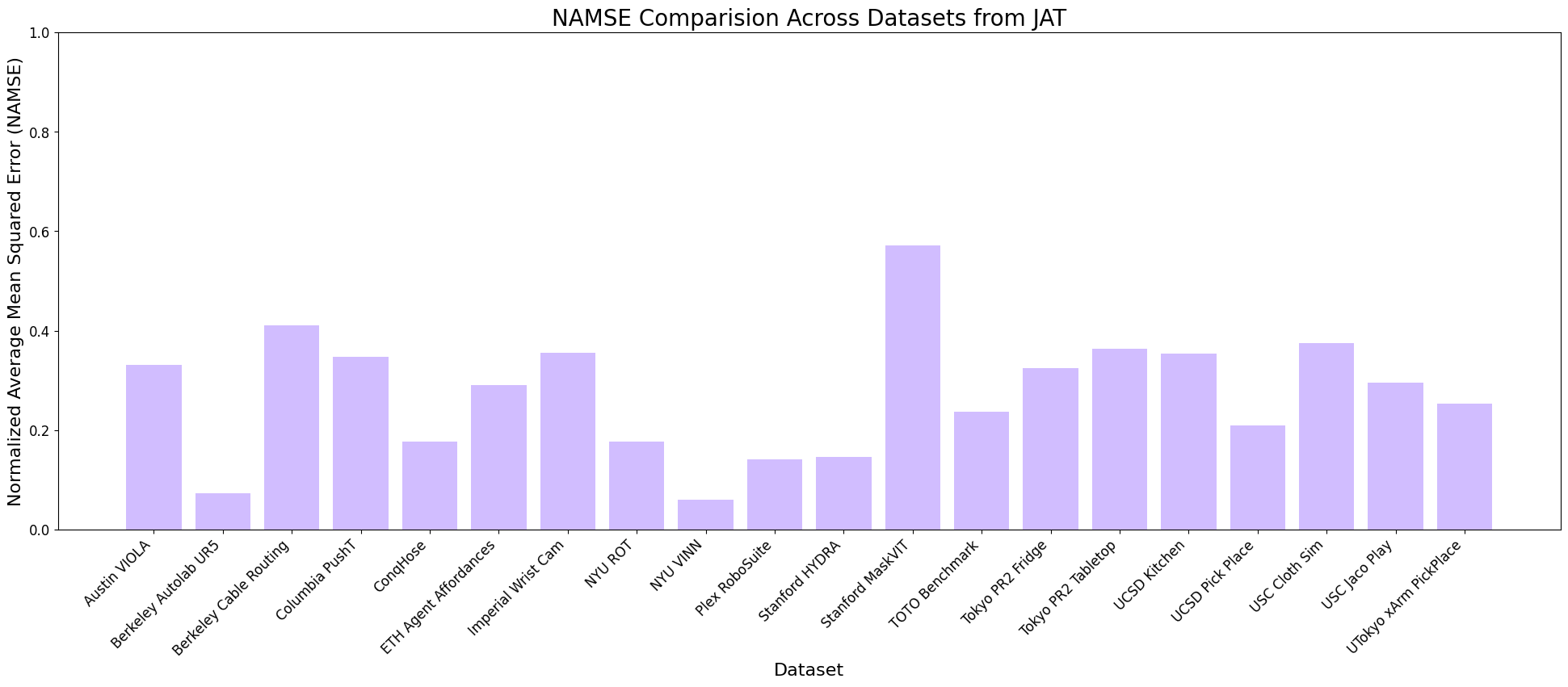
Normalized AMSE For JAT
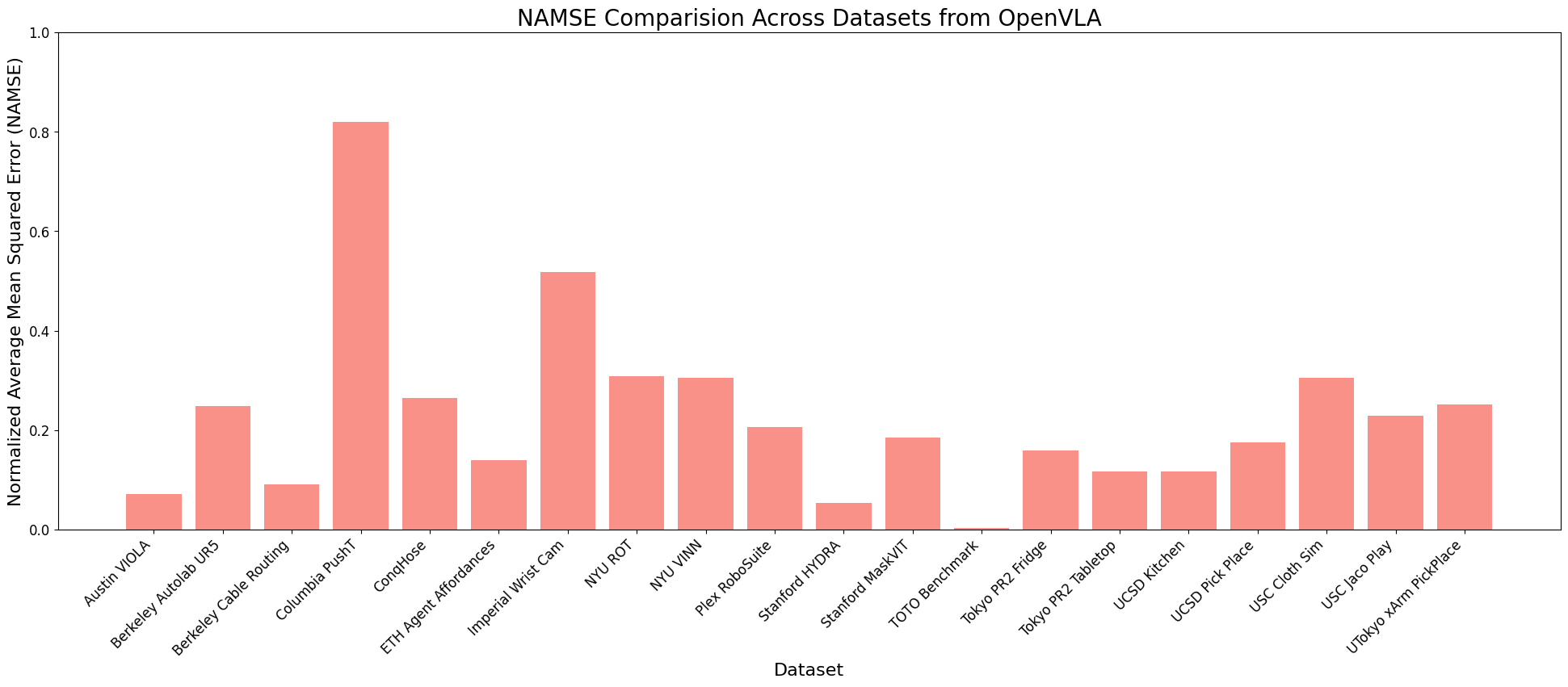
Normalized AMSE For OpenVLA
We observe that while JAT consistently shows higher AMSE (indicating worse performance) across most datasets, OpenVLA and GPT demonstrate more comparable performance levels, with AMSE typically below 0.5 for most datasets. For OpenVLA, we observe generally consistent performance across most datasets with AMSE in the 0.1-0.5 range, with best performance of all 3 models for tasks that fall within its training distribution, with notable exceptions in complex manipulation tasks. GPT shows comparable or slightly better performance on many datasets, particularly excelling in precise manipulation tasks. Both models maintain relatively stable performance across similar task types, though with different error profiles. The normalized analyses reveals that while absolute performance varies significantly, there are consistent patterns in what tasks are relatively more challenging for each model architecture. The success of GPT-4o's prompt engineering approach, in particular, suggests that providing structured context about action spaces and environmental constraints may be a key factor in achieving consistent performance across diverse tasks. This observation could inform future development of VLA models, suggesting that incorporating more explicit task and action space information could improve robustness and generalization capabilities.
Apart from open-sourcing our evaluation framework and profiling code, 2 technical contributions that we believe are novel to this work are:
The GenESIS (Generalizable Extendable Stratified Inference System) framework - A general framework for mapping VLMs to other modality classes, with particular emphasis on action spaces. This framework allows one to adapt a wide range of models to multiple types of tasks or datasets for scaling effectively while reducing the amount of engineering effort required. In MultiNet v0.1, GenESIS is used to evaluate GPT-4-o on the OpenX datasets. Since the GPT-4o is a VLM for general-purpose tasks, this involved setting up a well-researched instruction prompt, pre-processing of the input data in each dataset into a form that GPT-4 can consume, the management of chat history list for correct API calls, and conversion of the generated text outputs from the model to a format comparable with the ground truth action.
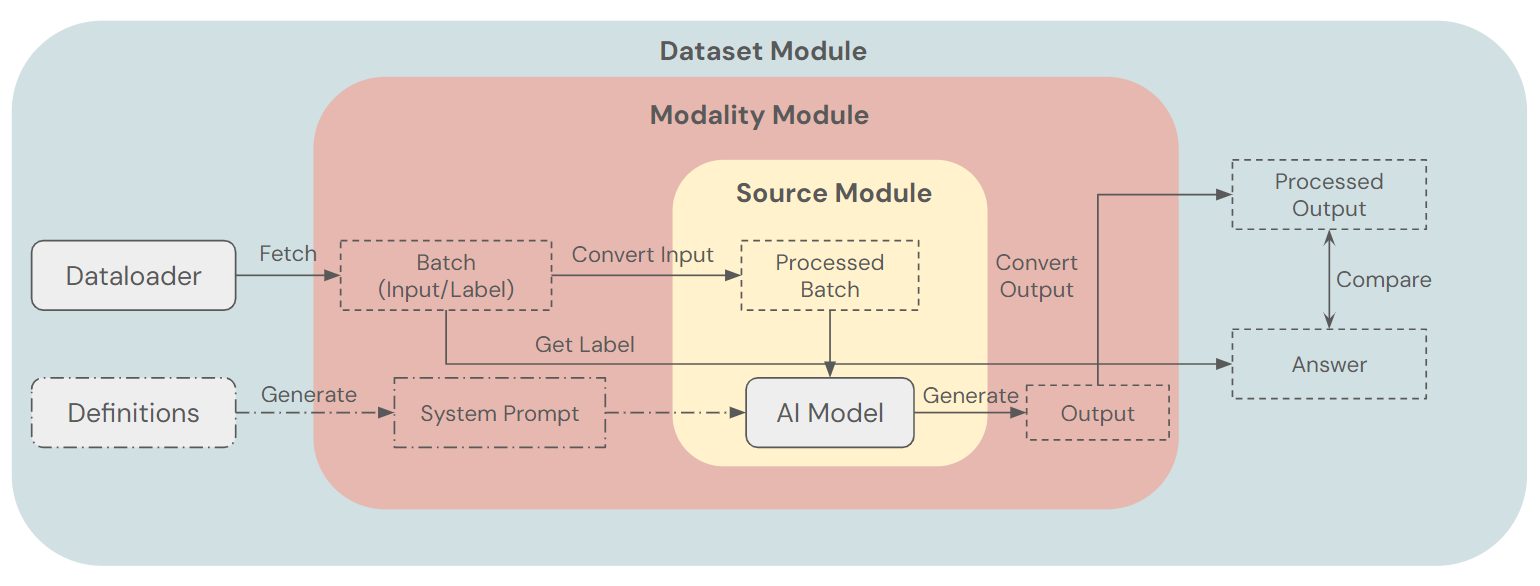
GenESIS Framework - used to adapt GPT-4o to the OpenX datasets
We also open-source the code to easily download any dataset within Multinet - typically from a variety of different sources. Lots of rich, diverse, highly valuable datasets in RL and Robotics are of different formats, from various different sources, in badly maintained states, with insufficient documentation. We open-source simple code that allows one to translate the downloaded control dataset shards into tensorflow dataset shards. Once translated to TFDS, the datasets can easily be utilized for training, fine-tuning, and evaluation.
We thank Rishabh Agarwal, Santiago Pedroza, Ahmed Khaled, Jianlan Luo, Stone Tao, Jaehyung Kim, Alex Irpan, Jeff Cui, Yuchen Cui, I-Chun Liu, Russell Mendonca, Yifeng Zhu, Hiroki Furuta, Nur Muhammad Shafiullah, Siddhant Haldar, Lili Chen, Kiana Ehsani, Benjamin Eysenbach, Dhruv Shah, Rose Hendrix, Rutav Shah, Giulio Schiavi, Homer Walke, Ilija Radosavovic, Shivin Dass for their contributions and helpful feedback in various capacities on this work.
@misc{guruprasad2024benchmarkingvisionlanguage,
title={Benchmarking Vision, Language, & Action Models on Robotic Learning Tasks},
author={Pranav Guruprasad and Harshvardhan Sikka and Jaewoo Song and Yangyue Wang and Paul Pu Liang},
year={2024},
eprint={2411.05821},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2411.05821},
} MultiNet
MultiNet